
はじめに
本文章では、「Google Cloud Platform」の「Speech-to-Text」を使用して、音声認識を行う方法について記載します。音声をテキストに変換することができますので、「話すと応答して何かを実行する」など、アイデア次第で色々なことを行うことができると思います。本文章では、「Speech-to-Text」の「無料トライアル」を使用します。
【備考】
「Speech-to-Text」は、音声を文字列テキストに変換してくれる「Google Cloud PlatformのAPIサービス」です。
実行環境
・ボード
Raspberry Pi 4 Model B
・OS
Raspberry Pi OS Lite
Release date: May 3rd 2023
System: 32-bit
Kernel version: 6.1
Debian version: 11 (bullseye)
・Python
Python 3.9.2
・pip
pip 23.2
使用マイク
本文章では、以下のUSBマイクを使用しています。
・SANWA SUPPLY MM-MCU06BK(サンプリングレート:48kHz、解像度:16bit)


事前準備
「Speech-to-Text API」を使用するためには、Googleアカウントを作成し、「Speech-to-Text API」を有効化する必要があります。
Googleアカウント作成
Googleアカウントを所有していない場合は作成してください。また、「Speech-to-Text API」を使用するためには、支払い方法の登録が必須のため登録を行ってください。
「Speech-to-Text API」の有効化
「Speech-to-Text API」を使用して音声をテキストに変換するには、「Speech-to-Text API」を有効化する必要があります。以下のURLにアクセスし有効化を行います。
【Google Cloud Speech-to-Text】
URL:https://cloud.google.com/speech-to-text/
1.以下の画面が表示されますので、「無料トライアル」をクリックします。
2.ログイン画面が表示されますので、事前に作成したアカウントIDを入力し、「次へ」をクリックします。
3.パスワード入力画面が表示されますのでパスワードを入力し、「次へ」をクリックしログインします。
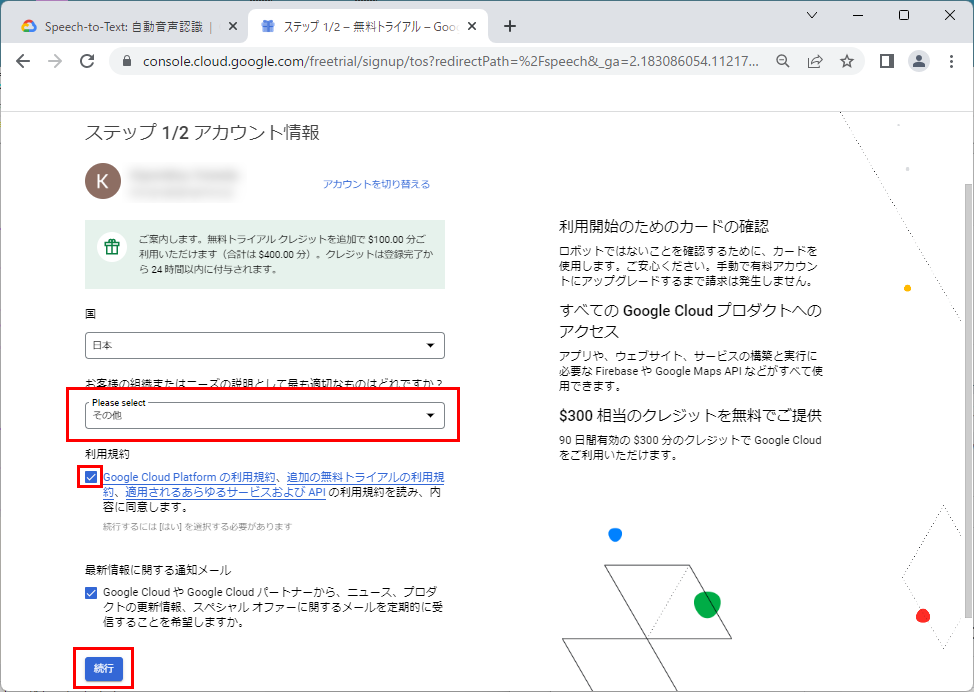
4.「Please Select」で適切な項目を選択し、「利用規約」にチェックマークを付け、「続行」をクリックします。
5.「無料トライアルを開始」をクリックします。
【備考】
Googleアカウントを作成した際に支払い方法を登録していない場合は、クレジットカード情報の登録が求められます。
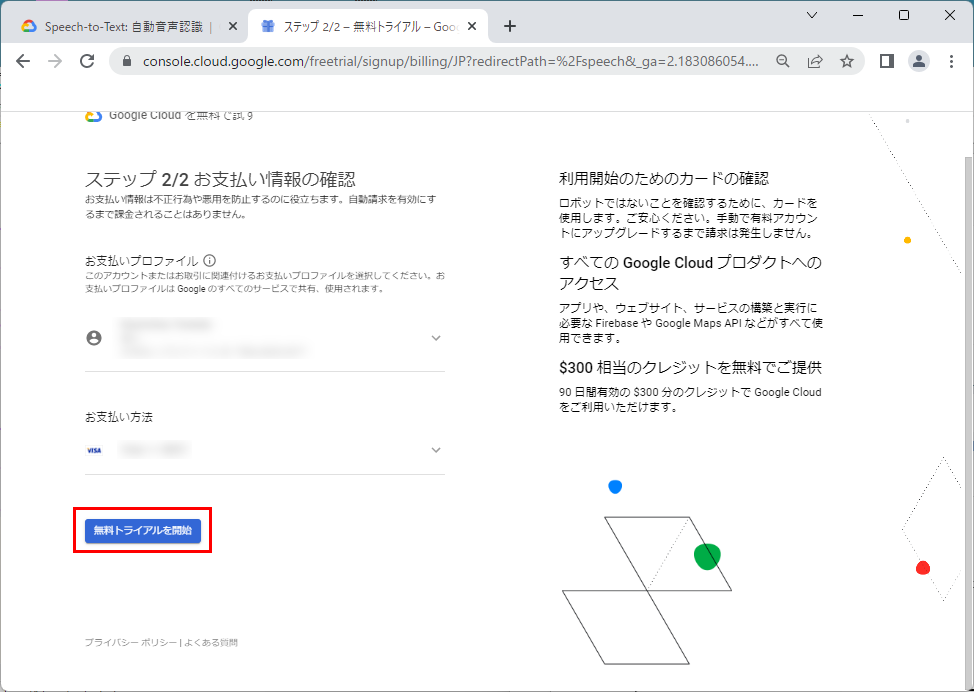
6.適切な理由を選択し、「次へ」をクリックします。
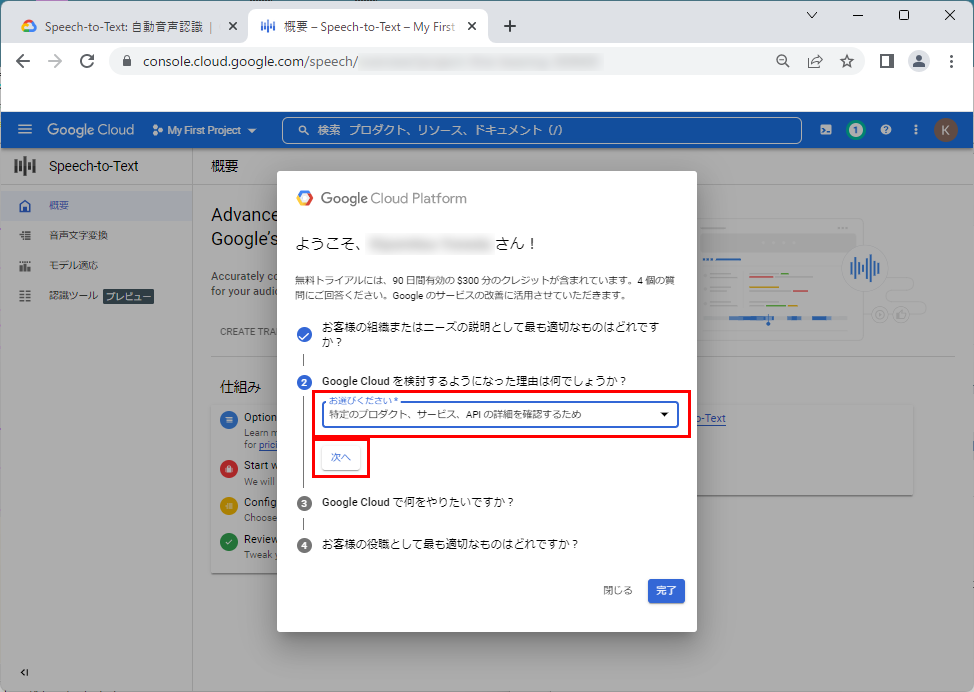
7.適切な項目を選択し、「次へ」をクリックします。
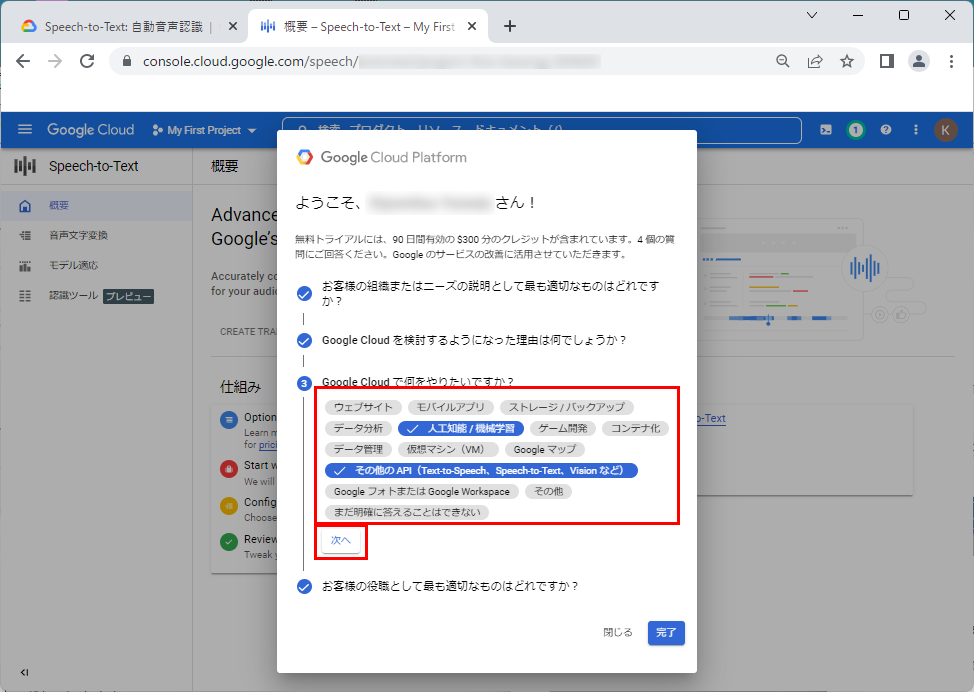
8.適切な項目を選択し、「完了」をクリックします。
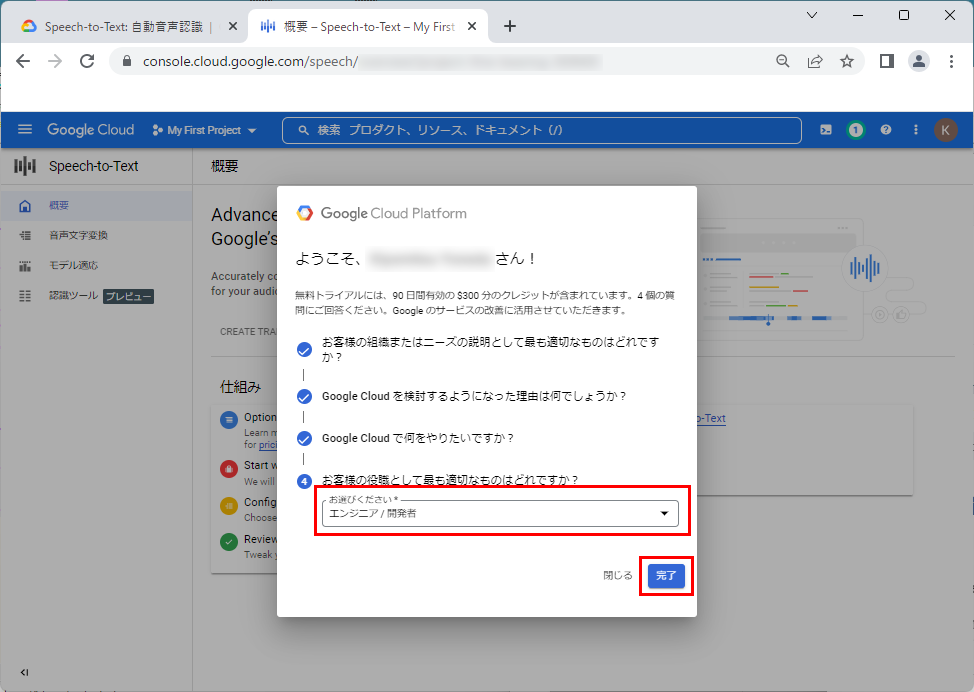
9.「今回はスキップ」をクリックします。
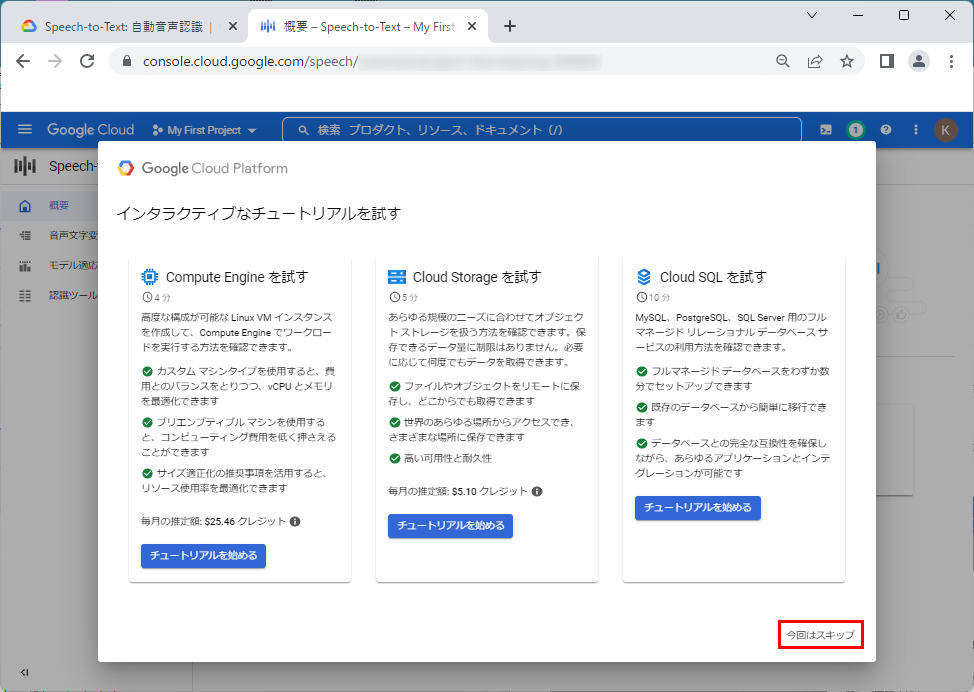
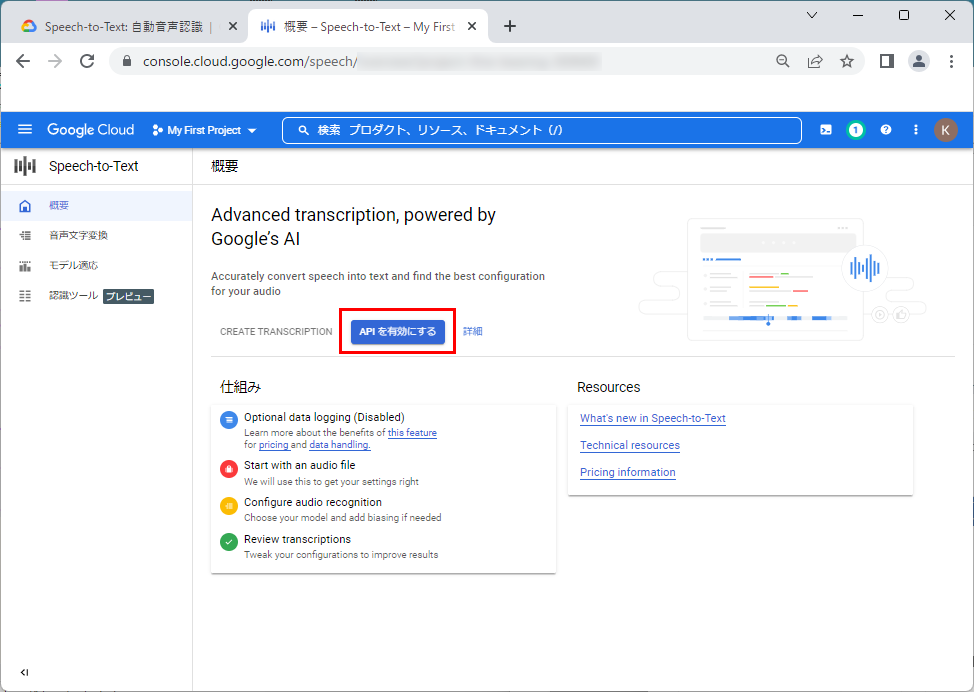
10.「Speech-to-Text API」を有効化するため、「APIを有効にする」をクリックします。
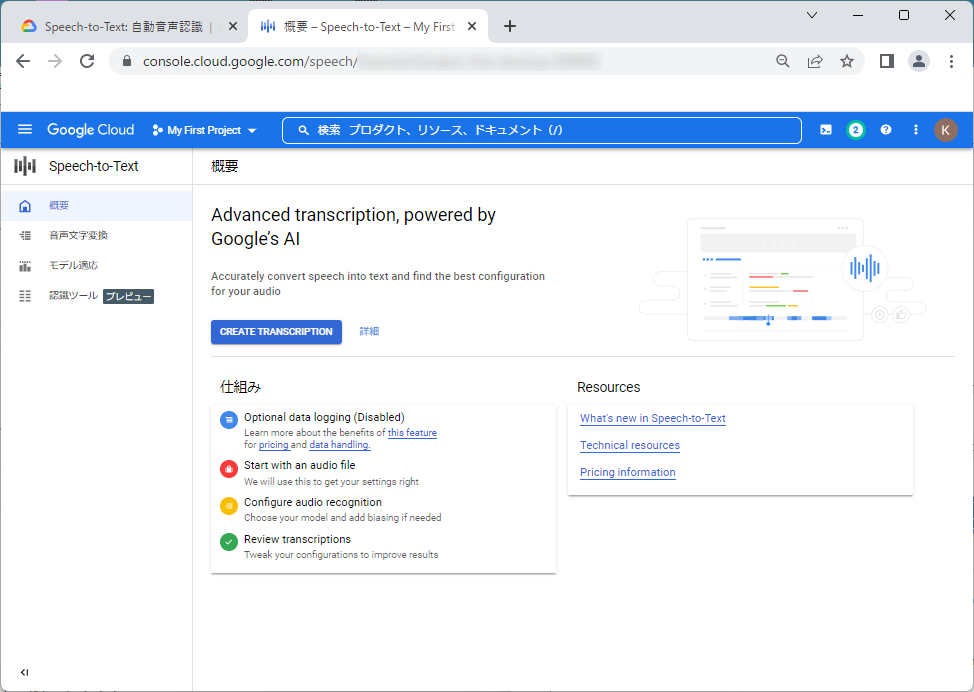
11.以下の画面が表示されれば、「Speech-to-Text API」の有効化は完了です。
サービスアカウントの作成
次に、「Speech-to-Text API」を使用するために必要なサービスアカウントを作成します。
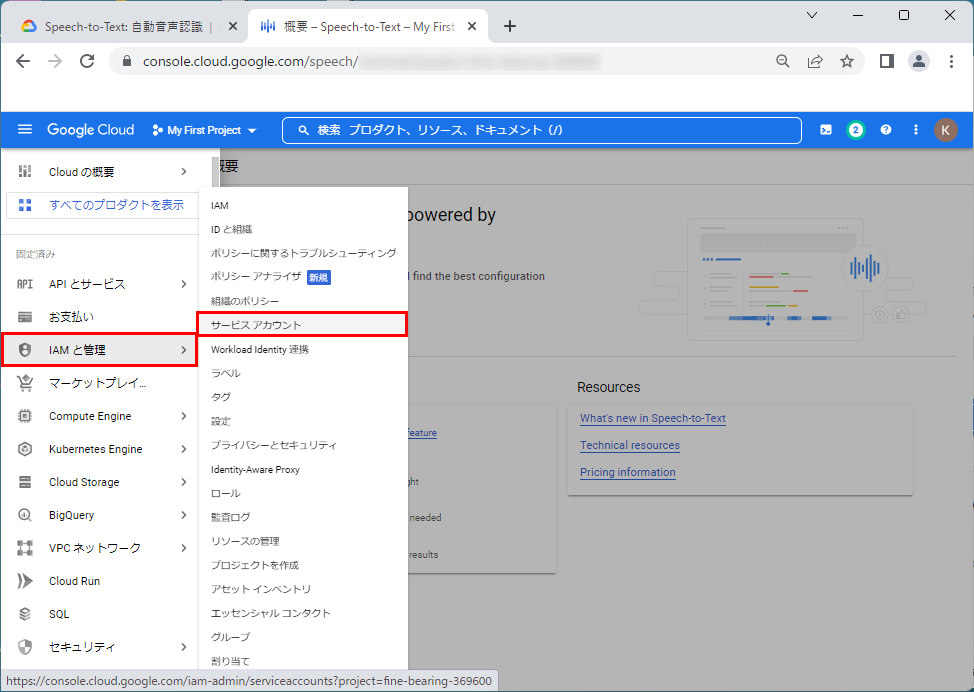
1.左上部の「三本線のアイコン」をクリックすると、「Cloudの概要」が表示されますので、「IAMと管理」⇒「サービスアカウント」をクリックします。
2.「+サービスアカウントの作成」をクリックします。
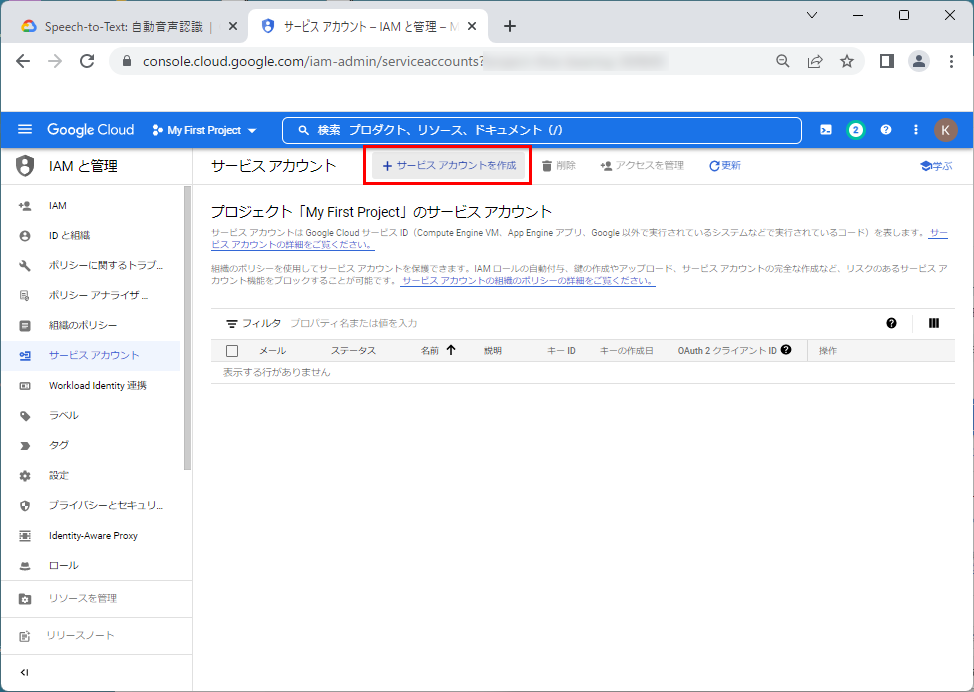
3.「サービスアカウント名」、「サービスアカウントの説明」を入力し、「作成して実行」をクリックします。
本文章では、それぞれ、「serv-speech」、「Speech-to-Textサービスアカウント」とします。
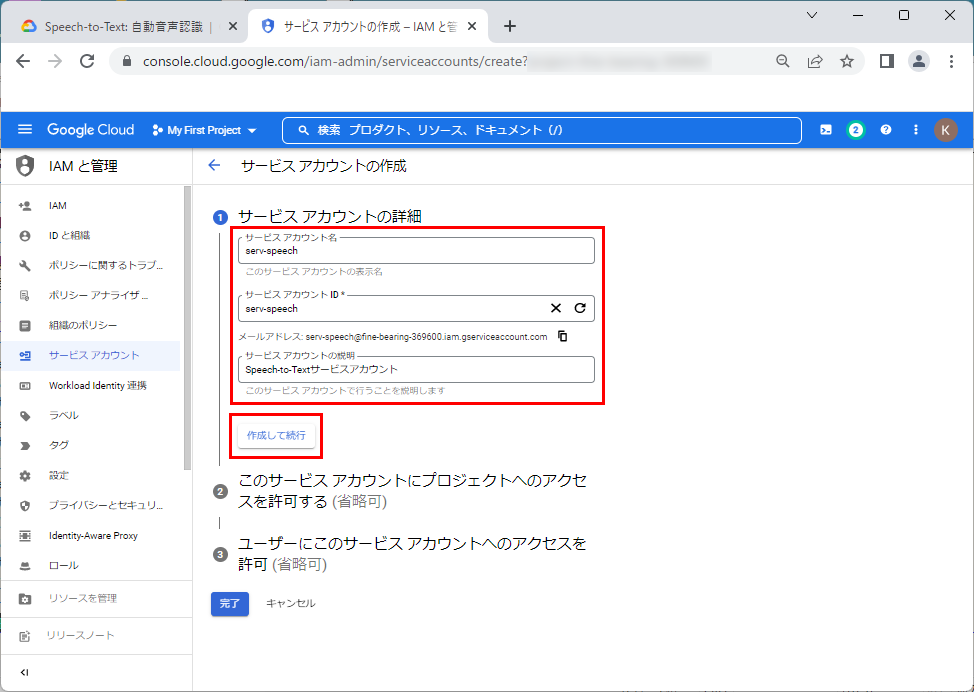
4.「ロールを選択」で、「基本」⇒「オーナー」を選択します。
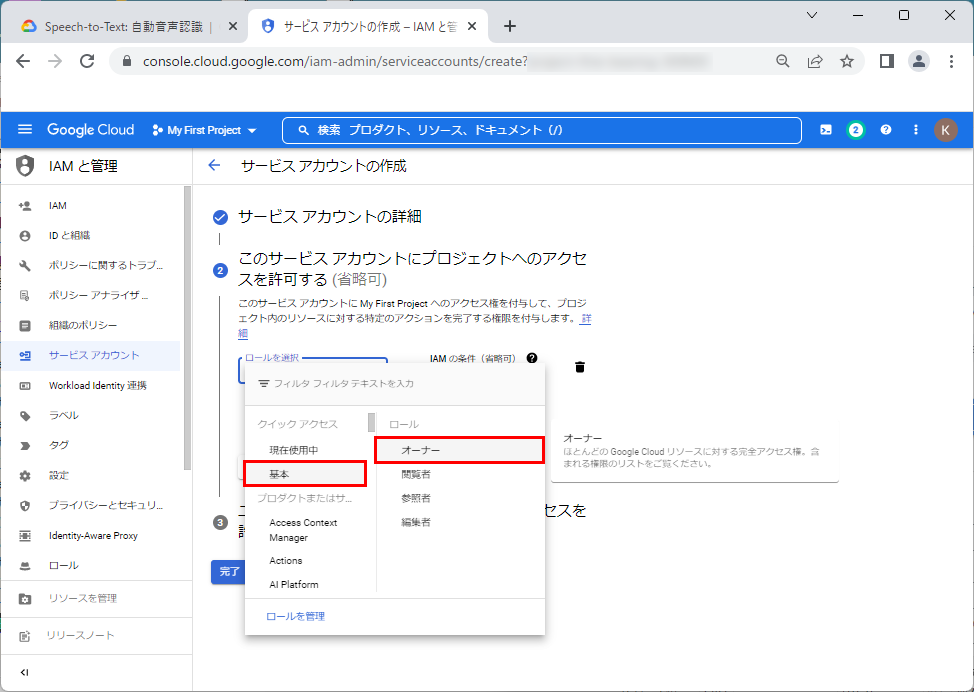
5.「続行」をクリックします。
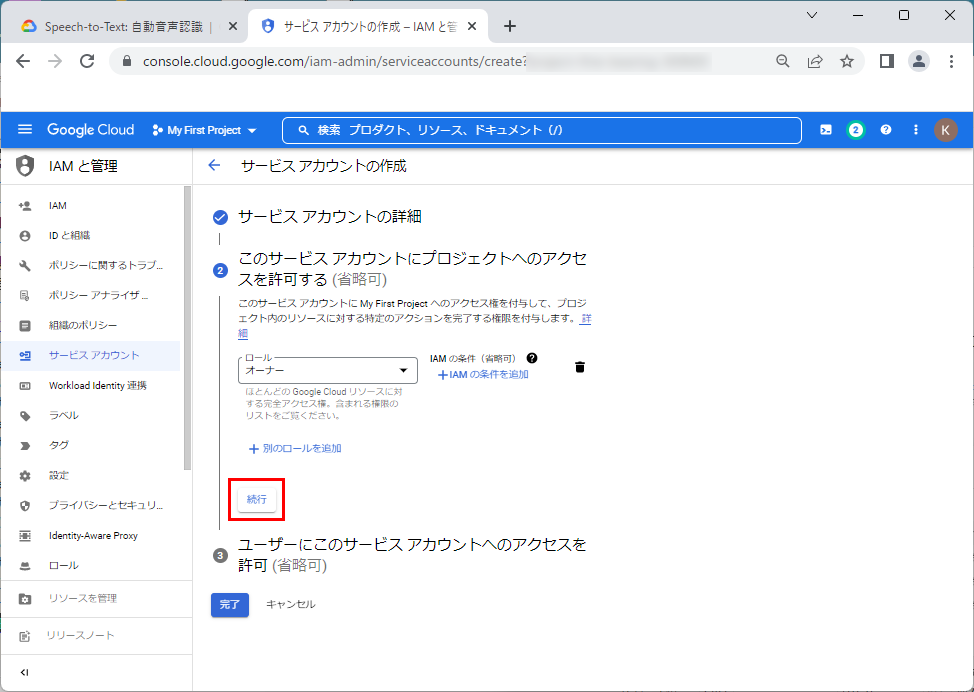
6.そのまま、「完了」をクリックします。
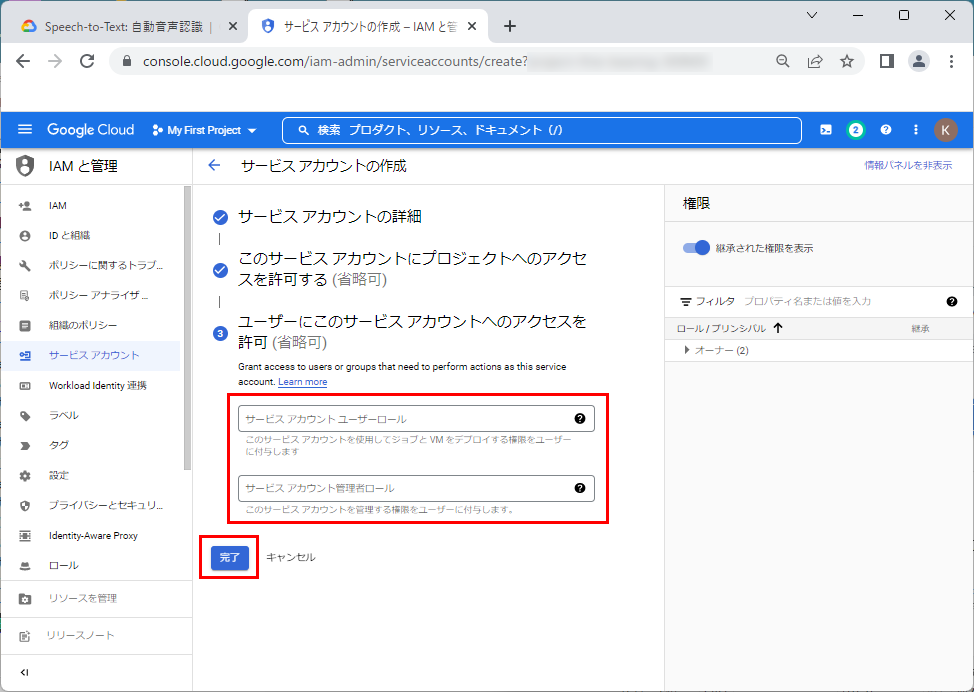
7.以下の画面のようにサービスアカウントが作成されます。
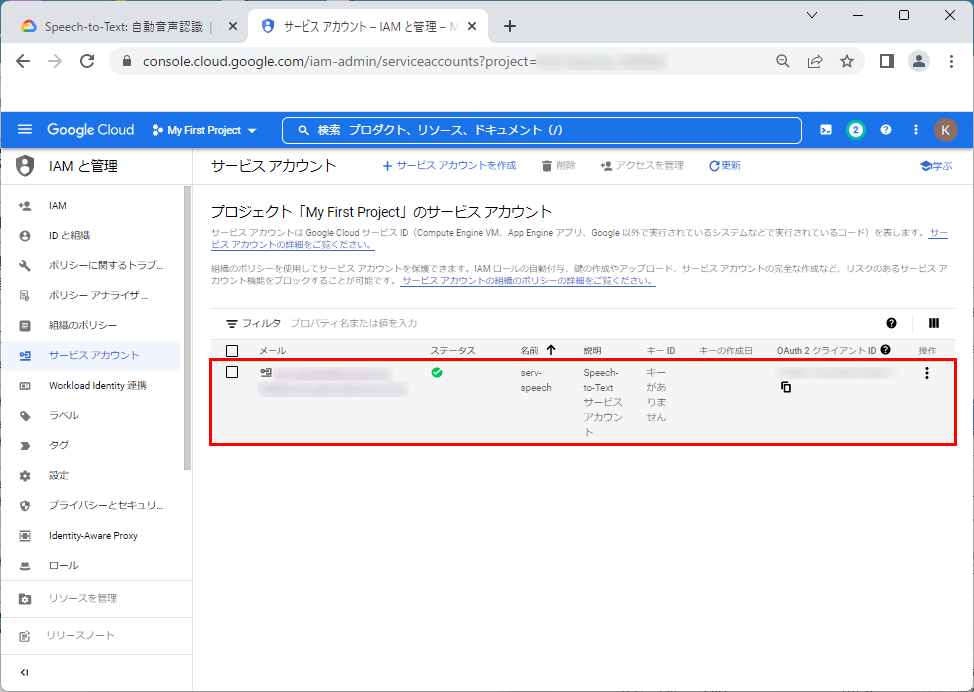
鍵の作成
1.次に「Speech-to-Text API」を使用する際に必要になる「鍵」を作成します。作成された「サービスアカウント」をクリックします。
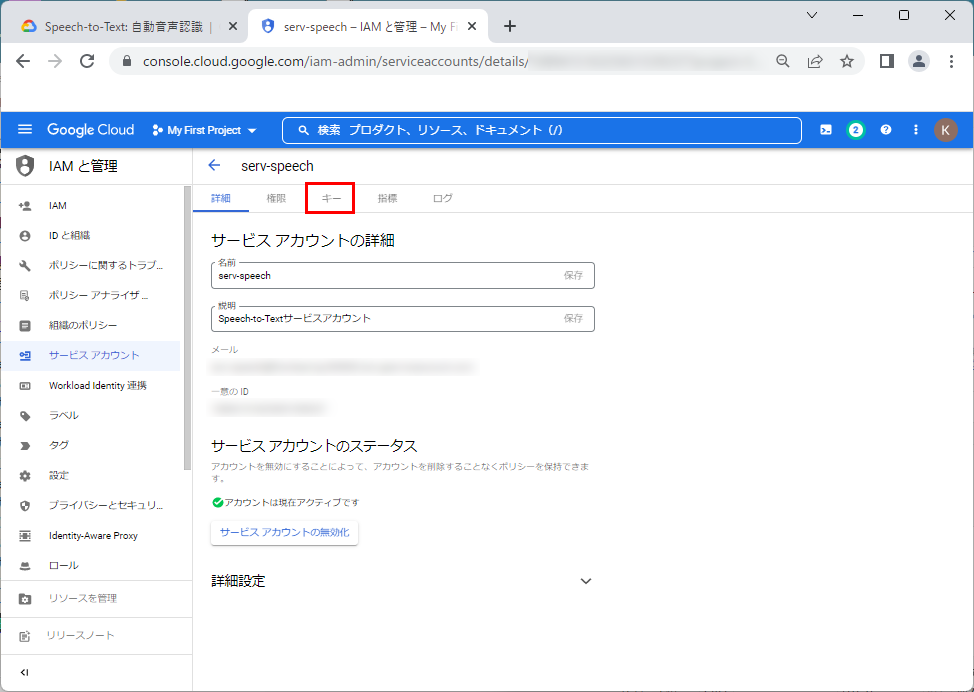
2.「キー」タブをクリックします。
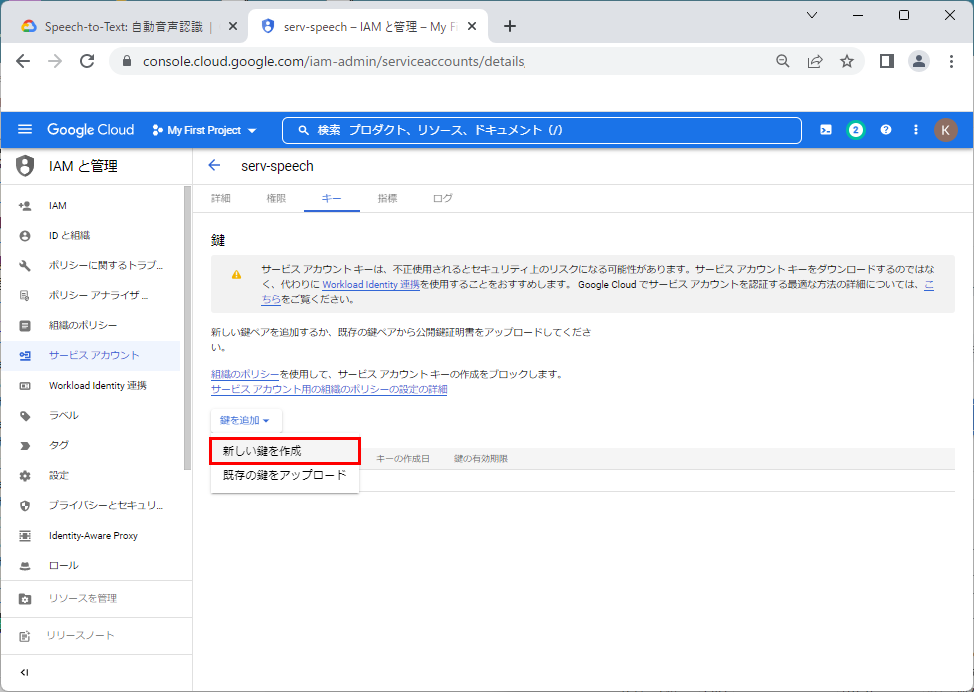
3.「鍵の追加」⇒「新しい鍵の作成」をクリックします。
4.作成する鍵の形式で「JSON(推奨)」を選択し、「作成」をクリックします。
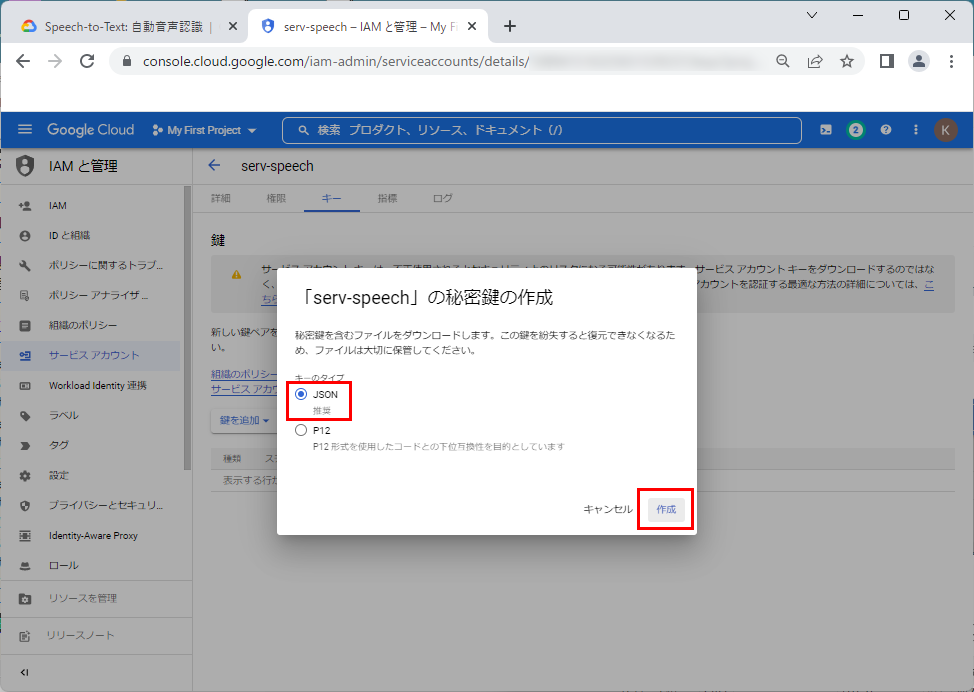
5.作成された「キー」を適当なディレクトリに保存します。
【注意】
この「キー」は、「Speech-to-Text API」を使用する際に必要になります。
また、この「キー」があれば「Speech-to-Text API」にアクセスすることができますので、保管には、注意してください。
6.「閉じる」をクリックします。
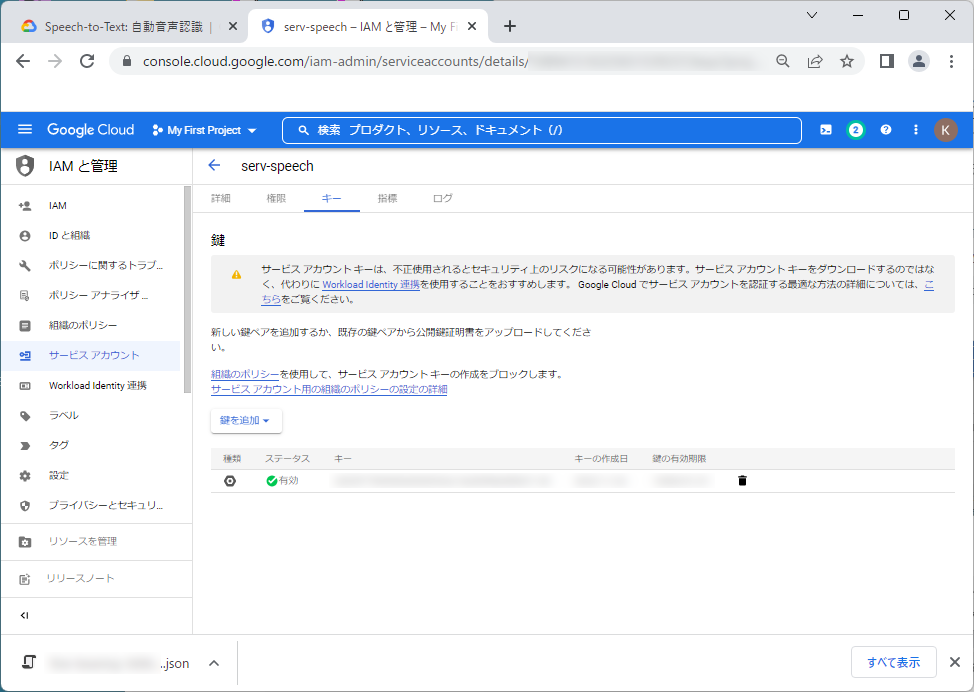
7.以下の画面のように、「鍵」が作成されていれば、「サービスアカウントの作成」および「鍵の作成」は完了です。
Python3実行環境の構築
Raspberry Pi OSの更新
はじめに、Raspberry Pi OSを最新の状態に更新します。
pi@raspberrypi:~ $ sudo apt update
pi@raspberrypi:~ $ sudo apt upgrade
pi@raspberrypi:~ $更新した内容を反映するため再起動します。
pi@raspberrypi:~ $ reboot更新後のRaspberry Pi OSのバージョンを確認します。
pi@raspberrypi:~ $ cat /proc/version
Linux version 6.1.21-v8+ (dom@buildbot) (aarch64-linux-gnu-gcc-8 (Ubuntu/Linaro 8.4.0-3ubuntu1) 8.4.0, GNU ld (GNU Binutils for Ubuntu) 2.34) #1642 SMP PREEMPT Mon Apr 3 17:24:16 BST 2023
pi@raspberrypi:~ $ uname -a
Linux raspberrypi 6.1.21-v8+ #1642 SMP PREEMPT Mon Apr 3 17:24:16 BST 2023 aarch64 GNU/Linux
pi@raspberrypi:~ $必要なパッケージのインストール
Python3実行環境の構築や「Speech-to-Text API」のサンプルコードを実行する際に必要なパッケージをインストールします。
pi@raspberrypi:~ $ sudo apt install wget git
pi@raspberrypi:~ $Python3のインストール
Python3およびvenvをインストールします。
pi@raspberrypi:~ $ sudo apt install python3 python3-dev python3-venv
pi@raspberrypi:~ $インストールしたバージョンを確認します。
pi@raspberrypi:~ $ python --version
Python 3.9.2
pi@raspberrypi:~ $【備考】
venvは、隔離された Python 環境を作成するツールです。
プロジェクトごとに実行環境を作成し、それらの環境を切り替えて使用することができます。
venvを使用することにより、他のプロジェクトに影響を与えることなく、プロジェクトに必要なパッケージをpipでインストールすることができます。
本文章では、pipの最新版をインストールします。
pi@raspberrypi:~ $ wget https://bootstrap.pypa.io/get-pip.py
pi@raspberrypi:~ $ sudo python3 get-pip.py
Successfully installed pip-22.3.1 setuptools-65.5.1 wheel-0.38.4
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
pi@raspberrypi:~ $インストールしたpipのバージョンを確認します。
pi@raspberrypi:~ $ pip --version
pip 23.2 from /usr/local/lib/python3.9/dist-packages/pip (python 3.9)
pi@raspberrypi:~ $PyAudioのインストール
本文章では、マイクから音声を扱うため、「PyAudio」オーディオI/Oライブラリを使用します。
【備考】
「PyAudio」は、多くのアプリケーションで利用されているオーディオI/Oライブラリである「PortAudio」をPythonで利用できるようにしたライブラリです。「PyAudio」を使用すると、オーディオを簡単に再生および録音できます。
【備考】
「PortAudio」は、無料で利用できるオープンソースのクロスプラットフォームで利用できるオーディオI/Oライブラリです。このライブラリを使用すると、C言語やC++言語を使用して、Windows、Macintosh OS X、Unix (OSS/ALSA) を含む多くのプラットフォームでコンパイルや実行できるシンプルなオーディオプログラムを記述することができます。このため、多くのアプリケーションのオーディオI/Oに「PortAudio」が使用されています。
はじめに、「PortAudio」のライブラリをインストールします。
pi@raspberrypi:~ $ sudo apt install libportaudio2
pi@raspberrypi:~ $「PyAudio」のインストールを行います。
pi@raspberrypi:~ $ pip install pyaudio
pi@raspberrypi:~ $マイクの動作確認
Raspberry Piで、USBマイクが正しく認識されていることを確認します。
USBマイクの認識確認
USBデバイスとして認識されていることを確認します。
【USBマイクの接続前】
pi@raspberrypi:~ $ lsusb
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 002: ID 2109:3431 VIA Labs, Inc. Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
pi@raspberrypi:~ $
【USBマイクの接続後】
pi@raspberrypi:~ $ lsusb
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 003: ID 0d8c:2800 C-Media Electronics, Inc. USB Microphone <== USBマイク
Bus 001 Device 002: ID 2109:3431 VIA Labs, Inc. Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
pi@raspberrypi:~ $ALSAコマンドを使用して、USBマイクが録音デバイスとして正しく認識されていることを確認します。
pi@raspberrypi:~ $ arecord -l
**** List of CAPTURE Hardware Devices ****
card 3: Microphone [USB Microphone], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
pi@raspberrypi:~ $同様に、ALSAコマンドを使用して、Raspberry Piのイヤホン・ジャックが、再生デバイスとして正しく認識されていることを確認します。
ここでは、[bcm2835 Headphones]として認識されていることが分かります。
pi@raspberrypi:~ $ aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: Headphones [bcm2835 Headphones], device 0: bcm2835 Headphones [bcm2835 Headphones] <== ピンジャック
Subdevices: 8/8
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
Subdevice #4: subdevice #4
Subdevice #5: subdevice #5
Subdevice #6: subdevice #6
Subdevice #7: subdevice #7
card 1: vc4hdmi0 [vc4-hdmi-0], device 0: MAI PCM i2s-hifi-0 [MAI PCM i2s-hifi-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 2: vc4hdmi1 [vc4-hdmi-1], device 0: MAI PCM i2s-hifi-0 [MAI PCM i2s-hifi-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 3: Microphone [USB Microphone], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
pi@raspberrypi:~ $デフォルトの再生デバイスとして、イヤフォン・ジャックが設定されていることを確認します。
ここでは、デフォルト、システムデフォルトの再生デバイスとして、イヤホン・ジャックが設定されていることが分かります。
pi@raspberrypi:~ $ aplay -L
null
Discard all samples (playback) or generate zero samples (capture)
hw:CARD=Headphones,DEV=0
bcm2835 Headphones, bcm2835 Headphones
Direct hardware device without any conversions
plughw:CARD=Headphones,DEV=0
bcm2835 Headphones, bcm2835 Headphones
Hardware device with all software conversions
default:CARD=Headphones
bcm2835 Headphones, bcm2835 Headphones
Default Audio Device
sysdefault:CARD=Headphones
bcm2835 Headphones, bcm2835 Headphones
Default Audio Device
dmix:CARD=Headphones,DEV=0
bcm2835 Headphones, bcm2835 Headphones
Direct sample mixing device
~(省略)~
pi@raspberrypi:~ $USBマイクの詳細は、ALSAコマンドを使用して確認することができます。
「-c」オプションでは、確認を行いたいカード番号を指定します。
本文章では、上記で確認したとおり、接続したUSBマイクは、「card 3」、「device 0」と認識されていますので、「-c3」と指定しています。
pi@raspberrypi:~ $ amixer -c3
Simple mixer control 'Speaker',0
Capabilities: pvolume pswitch pswitch-joined
Playback channels: Front Left - Front Right
Limits: Playback 0 - 37
Mono:
Front Left: Playback 17 [46%] [-20.00dB] [on]
Front Right: Playback 17 [46%] [-20.00dB] [on]
Simple mixer control 'Mic',0
Capabilities: pvolume pvolume-joined cvolume cvolume-joined pswitch pswitch-joined cswitch cswitch-joined
Playback channels: Mono
Capture channels: Mono
Limits: Playback 0 - 23 Capture 0 - 42
Mono: Playback 1 [4%] [-22.00dB] [off] Capture 38 [90%] [16.00dB] [on]
Simple mixer control 'Auto Gain Control',0
Capabilities: pswitch pswitch-joined
Playback channels: Mono
Mono: Playback [on]
pi@raspberrypi:~ $動作確認
本文章では、以下の「record_test.py」ファイルを作成し、PyAudioを使用してマイク音声を録音し、録音データをWAVEファイルに書き出します。
pi@raspberrypi:~ $ vi record_test.py
【記載内容】
#!/usr/bin/env python
import pyaudio
import wave
import sys
# フォーマット:16 bit Int
FORMAT = pyaudio.paInt16
# チャンネル数:1チャンネル(モノラル)
CHANNELS = 1
# サンプリングレート:44100Hz
RATE = 44100
# バッファあたりのフレーム数:512
CHUNK = 512
# 録音時間:5秒
RECORDING_TIME = 5
# 出力ファイル名
OUTPUT_FILENAME = "./output.wav"
# PyAudioのインスタンスを生成
p = pyaudio.PyAudio()
# 録音や再生するために使用するストリームをオーディオ パラメータを使用してオープン
stream = p.open(
# サンプリングレートを指定。
rate=RATE,
# チャンネル数を指定
channels=CHANNELS,
# サンプリングのサイズと形式を指定。
format=pyaudio.paInt16,
# 入力ストリームかどうかを指定。(デフォルトはFalse)
input=True,
# 出力ストリームかどうかを指定。(デフォルトはFalse)
output=False,
# 使用する入力デバイスのインデックスを指定。(デフォルトデバイスを使用)
input_device_index=None,
# 使用する出力デバイスのインデックスを指定。(デフォルトデバイスを使用)
output_device_index=None,
# バッファあたりのフレーム数を指定。
frames_per_buffer=CHUNK,
# すぐにストリームの実行を開始。(デフォルトはTrue)
start=True,
# 入力用のホスト API 固有のストリーム情報データ構造を指定。
input_host_api_specific_stream_info=None,
# 出力用のホストAPI固有のストリーム情報データ構造を指定。
output_host_api_specific_stream_info=None,
# 非ブロッキング(コールバック)操作のコールバック関数を指定。(デフォルトはNoneで、ブロック操作)
stream_callback=None
)
# 録音開始
print("録音中...")
frames = []
for i in range(0, int(RATE / CHUNK * RECORDING_TIME)):
data = stream.read(CHUNK)
frames.append(data)
print("録音終了.")
# ストリームを停止。
stream.stop_stream()
# ストリームをクローズ。
stream.close()
# PyAudioのインスタンスを解放
p.terminate()
# 録音データのファイルへの書き出し
wf = wave.open(OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
pi@raspberrypi:~ $正しくWAVファイルが作成されていることを確認します。
pi@raspberrypi:~ $ ls -l
-rw-r--r-- 1 pi pi 440364 Nov 29 20:00 output.wav
pi@raspberrypi:~ $以下の「play_test.py」ファイルを作成し、PyAudioを使用して録音したWAVEファイルが正しく再生できることを確認します。
pi@raspberrypi:~ $ vi play_test.py
【記載内容】
#!/usr/bin/env python
import pyaudio
import wave
# バッファあたりのフレーム数:512
CHUNK_SIZE = 512
# 入力ファイル名
INPUT_FILENAME = "./output.wav"
# WAVEファイルのオープン
wf = wave.open(INPUT_FILENAME, 'rb')
# PyAudioのインスタンスを生成
p = pyaudio.PyAudio()
stream = p.open(
format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True
)
# WAVEファイルからのCHUNK_SIZE数のデータ読み込み
# ストリームへのデータを書き込む
data = wf.readframes(CHUNK_SIZE)
while len(data) > 0:
stream.write(data)
data = wf.readframes(CHUNK_SIZE)
# ストリームを停止。
stream.stop_stream()
# ストリームをクローズ。
stream.close()
# PyAudioのインスタンスを解放。
p.terminate()
pi@raspberrypi:~ $問題なくイヤフォンから再生できれば、動作確認が完了です。
Speech-to-Textを使用した音声の文字列変換
本文章では、「Google Cloud Platform」の公式ホームページで公開されている「Python 非ストリーミングおよびストリーミング音声認識サンプル」を使用して、「Speech-to-Text API」に音声データを送信し、その音声データの文字変換テキストを受信します。
サンプルコードのダウンロード
Python用の音声認識サンプルコードをダウンロードします。
(GitHubのWeb URLが変更されたようです。)
pi@raspberrypi:~ $ git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git
pi@raspberrypi:~ $ 以下のように、「python-docs-samples」というディレクトリが作成されます。
pi@raspberrypi:~ $ ls -l
total 2552
-rw-r--r-- 1 pi pi 2605400 Jul 15 19:15 get-pip.py
drwxr-xr-x 92 pi pi 4096 Jul 20 20:48 python-docs-samples
pi@raspberrypi:~ $本文章では、マイクからの音声データを文字列テキストに変換するため、「microphone」サンプルコードを使用します。「python-docs-samples/speech/microphone/」ディレクトリに移動します。
pi@raspberrypi:~ $ cd python-docs-samples/speech/microphone/
pi@raspberrypi:~/python-docs-samples/speech/microphone $venvを使用して、仮想実行環境を作成します。本文章では、仮想実行環境の名前を「env」とします。
pi@raspberrypi:~/python-docs-samples/speech/microphone $ python3 -m venv env
pi@raspberrypi:~/python-docs-samples/speech/microphone $「env」仮想実行環境を有効化します。有効化されると、コマンドプロンプトの先頭に「(仮想実行環境名)」が記載されます。
pi@raspberrypi:~/python-docs-samples/speech/microphone $ source env/bin/activate
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $サンプルの実行に必要な依存パッケージをインストールします。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ pip install -r requirements.txt
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Collecting google-cloud-speech==2.20.0
~(略)~
Installing collected packages: pyasn1, urllib3, six, rsa, pyasn1-modules, protobuf, idna, charset-normalizer, certifi, cachetools, requests, grpcio, googleapis-common-protos, google-auth, grpcio-status, google-api-core, proto-plus, pyaudio, google-cloud-speech
Successfully installed cachetools-5.3.1 certifi-2023.5.7 charset-normalizer-3.2.0 google-api-core-2.11.1 google-auth-2.22.0 google-cloud-speech-2.20.0 googleapis-common-protos-1.59.1 grpcio-1.56.2 grpcio-status-1.56.2 idna-3.4 proto-plus-1.22.3 protobuf-4.23.4 pyasn1-0.5.0 pyasn1-modules-0.3.0 pyaudio-0.2.13 requests-2.31.0 rsa-4.9 six-1.16.0 urllib3-1.26.16
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $サンプルコードの「transcribe_streaming_mic.py」では、言語の設定が「language_code=”en-US”」になっているため、日本語変換できるように「language_code=”ja-JP”」に変更します。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ vi transcribe_streaming_mic.py
【変更内容】
~(省略)~
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
#language_code = "en-US" # a BCP-47 language tag <-- コメントアウト
language_code = "ja_JP" <-- 追記
~(省略)~
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $キーの設定
「Speech-to-Text API」を使用するためには、事前に作成したキーを環境変数「GOOGLE_APPLICATION_CREDENTIALS」に設定する必要があります。
本文章では、キーを「/home/pi/ServiceAccountKey」ディレクトリに保存しています。
キー名は、ダウンロードしたキー名に適宜置き換えてください。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ export GOOGLE_APPLICATION_CREDENTIALS="/home/pi/ServiceAccountKey/[DownloadKeyName].json"
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $動作確認
音声認識サンプルコードを実行する準備が完了しましたので動作確認を行います。
言葉を発生し、正しく文字列テキストに変換されるか確認します。
本文章では、「明日の天気は」と発声したところ、正しく文字列テキストに変換されました。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ python3 transcribe_streaming_mic.py
明日の天気は
KeyboardInterrupt
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $【参考】
本文章で使用したUSBマイクのサンプリングレートは「48kHz」であったため、サンプリングレート「16kHz」に対応していませんでした。このため、ダウンロードしたサンプルコードを実行すると、以下のようなエラーが表示されました。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ python3 transcribe_streaming_mic.py
~(省略)~
File "/home/pi/python-docs-samples/speech/microphone/env/lib/python3.9/site-packages/pyaudio.py", line 445, in __init__
self._stream = pa.open(**arguments)
OSError: [Errno -9997] Invalid sample rate
(env) pi@raspberrypi:~/python-speech/samples/microphone $本文章では、サンプリングレートをUSBマイクのサンプリングレート「RATE=48000」(48kHz)に変更し、このデータを3個飛ばしで扱い、サンプリングレート「16000」(16kHz)でサンプリングしたデータとして使用しています。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ vi transcribe_streaming_mic.py
~(省略)~
# Audio recording parameters
RATE = 16000
MICROPHONE_RATE = 48000 <-- マイク用のサンプリングレートを追記
CHUNK = int(MICROPHONE_RATE / 10) # 100ms <-- CHUNKサイズの修正
~(省略)~
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data[::3]) <-- 3個飛ばしのデータを使用(16kHzデータ)
return None, pyaudio.paContinue
~(省略)~
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
#language_code = "en-US" # a BCP-47 language tag
language_code = "ja-JP"
~(省略)~
with MicrophoneStream(MICROPHONE_RATE, CHUNK) as stream: <-- マイク用のサンプリングレート、CHUNKに修正
audio_generator = stream.generator()
requests = (
speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator
)
~(省略)~
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $試しに、以下の適当な音声をテキストに変換してみましたが、正しく変換されました。
高い精度で、音声認識ができるようです。
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $ python3 transcribe_streaming_mic.py
哺乳瓶は15 L もあったんだすごいな初めての試みでどうやって飲ませるか分からず大変だったよ
(env) pi@raspberrypi:~/python-docs-samples/speech/microphone $以上、終了です。

