
はじめに
公式ページのSwift 言語ガイド「The Swift Programming Language Swift 5.3」に基づき記載いたします。本ページでは、「文字列と文字」について記載いたします。
記載内容に誤り等ございましたら、ご連絡をいただければ幸いです。
3. 文字列と文字
文字列は、「hello、world」や「albatross」などの一連の文字です。Swift文字列は、String型で表されます。文字列の内容には、文字値のコレクションなど、さまざまな方法でアクセスできます。
SwiftのString型とCharacter型は、コード内のテキストを操作するための高速でUnicode準拠の方法を提供します。文字列の作成と操作の構文は軽量で読みやすく、Cに似た文字列リテラル構文を使用します。文字列の連結は、2つの文字列を+演算子で組み合わせるのと同じくらい簡単で、文字列の可変性は、Swiftの他の値と同様に、定数または変数のいずれかを選択することによって管理されます。文字列補間と呼ばれるプロセスで、文字列を使用して、定数、変数、リテラル、および式をより長い文字列に挿入することもできます。これにより、表示、保存、および印刷用のカスタム文字列値を簡単に作成できます。
この構文の単純さにもかかわらず、SwiftのString型は、高速で最新の文字列実装です。すべての文字列は、エンコーディングに依存しないUnicode文字で構成されており、さまざまなUnicode表現でこれらの文字にアクセスするためのサポートを提供します。
注意
SwiftのString型は、FoundationのNSStringクラスとブリッジされています。Foundationは、Stringを拡張して、NSStringで定義されたメソッドを公開します。つまり、Foundationをインポートすると、キャストせずにStringでこれらのNSStringメソッドにアクセスできます。
FoundationとCocoaでStringを使用する方法の詳細については、StringとNSString間のブリッジングを参照してください。
3.1. 文字列リテラル
事前に定義された文字列値を文字列リテラルとしてコード内に含めることができます。文字列リテラルは、二重引用符(“)で囲まれた文字のシーケンスです。
定数または変数の初期値として文字列リテラルを使用します。
let someString = "いくつかの文字列リテラル値"Swiftは、文字列リテラル値で初期化されるため、someString定数の文字列型を推測することに注意してください。
3.2. 複数行の文字列リテラル
複数行にまたがる文字列が必要な場合は、複数行の文字列リテラル(3つの二重引用符で囲まれた文字のシーケンス)を使用します。
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""複数行の文字列リテラルには、開始引用符と終了引用符の間のすべての行が含まれます。文字列は、開始引用符(“””)の後の最初の行で始まり、終了引用符の前の行で終わります。つまり、下の文字列はどちらも改行で開始または終了しません。
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""ソースコードの複数行の文字列リテラル内に改行が含まれている場合、その改行は文字列の値にも表示されます。ソースコードを読みやすくするために改行を使用したいが、改行を文字列の値の一部にしたくない場合は、これらの行の最後に円記号()を記述します。
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""改行で開始または終了する複数行の文字列リテラルを作成するには、最初または最後の行として空白行を記述します。 例えば:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""複数行の文字列は、周囲のコードと一致するようにインデントできます。 閉じ引用符(“””)の前の空白は、他のすべての行の前に無視する空白をSwiftに指示します。ただし、終了引用符の前に加えて行の先頭に空白を書き込むと、その空白が含まれます。

上記の例では、複数行の文字列リテラル全体がインデントされていても、文字列の最初と最後の行は空白で始まりません。中央の行には、閉じ引用符よりも多くのインデントがあるため、余分な4スペースのインデントで始まります。
3.3. 文字列リテラルの特殊文字
文字列リテラルには、次の特殊文字を含めることができます。
- エスケープされた特殊文字\0(null文字)、\(バックスラッシュ)、\t(水平タブ)、\n(改行)、\r(キャリッジリターン)、\”(二重引用符)、および\'(単一クォーテーションマーク)
- \u{n}として記述された任意のUnicodeスカラー値。nは1〜8桁の16進数です(Unicodeについては以下のUnicodeで説明します)
以下のコードは、これらの特殊文字の4つの例を示しています。wiseWords定数には、2つのエスケープされた二重引用符が含まれています。DollarSign、blackHeart、およびsparklingHeart定数は、Unicodeスカラー形式を示しています。
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496複数行の文字列リテラルは1つではなく3つの二重引用符を使用するため、複数行の文字列リテラル内にエスケープせずに二重引用符(“)を含めることができます。複数行の文字列にテキスト”””を含めるには、少なくとも1つの引用符をエスケープします。
例えば:
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""3.4. 拡張文字列区切り文字
拡張区切り文字内に文字列リテラルを配置して、効果を呼び出さずに文字列に特殊文字を含めることができます。 文字列を引用符(“)で囲み、数字記号(#)で囲みます。たとえば、文字列リテラル#”Line 1 \ nLine 2″#を印刷すると、文字列が2行にまたがって印刷されるのではなく、改行エスケープシーケンス(\n)が印刷されます。
文字列リテラル内の文字の特殊効果が必要な場合は、エスケープ文字()に続く文字列内の番号記号の数と一致させてください。たとえば、文字列が#”Line 1\nLine 2″#で、行を分割したい場合は、代わりに#”Line 1#nLine 2″#を使用できます。同様に、###”Line1###nLine2″###も改行します。
拡張区切り文字を使用して作成された文字列リテラルは、複数行の文字列リテラルにすることもできます。拡張区切り文字を使用して、テキスト”””を複数行の文字列に含め、リテラルを終了するデフォルトの動作をオーバーライドできます。次に例を示します。
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
"""#3.5. 空の文字列の初期化
より長い文字列を作成するための開始点として空の文字列値を作成するには、空の文字列リテラルを変数に割り当てるか、初期化構文を使用して新しい文字列インスタンスを初期化します。
var emptyString = "" // 空の文字列リテラル
var anotherEmptyString = String() // 初期化構文
// これらの2つの文字列は両方とも空であり、互いに同等ですブール値のisEmptyプロパティをチェックして、文字列値が空かどうかを確認します。
if emptyString.isEmpty {
print("Nothing to see here")
}
// Prints "Nothing to see here"
「ここには何も表示されません」と出力されます3.6. 文字列の可変性
特定の文字列を変数(この場合は変更可能)または定数(この場合は変更不可)に割り当てることで、特定の文字列を変更できるかどうかを指定します。
var variableString = "Horse"
variableString += " and carriage"
// variableStringは、"Horse and carriage"になりました
let constantString = "Highlander"
constantString += " and another Highlander"
// これはコンパイル時エラーを報告します - 定数文字列は変更できません注意
このアプローチは、2つのクラス(NSStringとNSMutableString)から選択して文字列を変更できるかどうかを示すObjective-CとCocoaの文字列変更とは異なります。
3.7. 文字列は値型
Swiftの文字列型は値型です。新しい文字列値を作成すると、その文字列値は、関数またはメソッドに渡されるとき、または定数または変数に割り当てられるときにコピーされます。いずれの場合も、既存の文字列値の新しいコピーが作成され、元のバージョンではなく、新しいコピーが渡されるか割り当てられます。値型については、構造体と列挙型は値型で説明されています。
Swiftのデフォルトでの文字列のコピー動作により、関数またはメソッドが文字列値を渡したときに、それがどこから来たかに関係なく、その正確な文字列値を所有していることが明確になります。渡された文字列は、自分で変更しない限り変更されないことを確信できます。
舞台裏では、Swiftのコンパイラが文字列の使用を最適化して、絶対に必要な場合にのみ実際のコピーが行われるようにします。これは、値型として文字列を操作するときに常に優れたパフォーマンスが得られることを意味します。
3.8. 文字列の操作
for-inループを使用して文字列を反復処理することにより、文字列の個々の文字値にアクセスできます。
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶for-inループについては、For-Inループで説明しています。
または、文字型の注釈を指定して、単一文字の文字列リテラルからスタンドアロンの文字定数または変数を作成することもできます。
let exclamationMark: Character = "!"文字列値は、文字値の配列を引数として初期化子に渡すことで作成できます。
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// "Cat!🐱"が出力されます3.9. 文字列と文字の連結
文字列値は、加算演算子(+)を使用して一緒に加算(または連結)して、新しい文字列値を作成できます。
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcomeは、"hello there"に等しい加算代入演算子(+=)を使用して、既存の文字列変数に文字列値を追加することもできます。
var instruction = "look over"
instruction += string2
// instructionは、"look over there"と等しくなりましたString型のappend()メソッドを使用して、String変数にCharacter値を追加できます。
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcomeは、"hello there!"と等しくなりました注意
文字値には単一の文字のみを含める必要があるため、既存の文字変数に文字列または文字を追加することはできません。
複数行の文字列リテラルを使用して長い文字列の行を作成する場合は、最後の行を含め、文字列内のすべての行を改行で終了する必要があります。例えば:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// 2行を出力します:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// 3行を出力します:
// one
// two
// three上記のコードでは、badStartをendと連結すると、2行の文字列が生成されますが、これは望ましい結果ではありません。badStartの最後の行は改行で終了しないため、その行は最後行との最初が結合されます。対照的に、goodStartの両方の行は改行で終了するため、endと組み合わせると、予想どおり、結果は3行になります。
3.10. 文字列補間
文字列補間は、定数、変数、リテラル、および式の組み合わせから、それらの値を文字列リテラル内に含めることにより、新しい文字列値を構築する方法です。文字列補間は、単一行と複数行の両方の文字列リテラルで使用できます。文字列リテラルに挿入する各項目は、円記号(\)で始まる括弧のペアで囲まれます。
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// messageは、"3 times 2.5 is 7.5"です上記の例では、multiplierの値は(multiplier)として文字列リテラルに挿入されます。このプレースホルダーは、実際の文字列を作成するために文字列補間が評価されるときに、multiplierの実際の値に置き換えられます。
multiplierの値も、文字列の後半にある大きな式の一部です。この式は、Double(multiplier)2.5の値を計算し、結果(7.5)を文字列に挿入します。この場合、式は文字列リテラル内に含まれていると(Double(multiplier)2.5)として記述されます。
拡張文字列区切り文字を使用して、文字列補間として扱われる文字を含む文字列を作成できます。 例えば:
print(#"Write an interpolated string in Swift using \(multiplier)."#)
// "Write an interpolated string in Swift using \(multiplier)."を出力します拡張区切り文字を使用する文字列内で文字列補間を使用するには、円記号の後の番号記号の数を、文字列の最初と最後の番号記号の数と一致させます。 例えば:
print(#"6 times 7 is \#(6 * 7)."#)
// "6 times 7 is 42."を出力します注意
補間された文字列内の括弧内に書き込む式には、エスケープされていない円記号()、キャリッジリターン、または改行を含めることはできません。 ただし、他の文字列リテラルを含めることができます。
3.11. Unicode
Unicodeは、さまざまな書記体系でテキストをエンコード、表現、および処理するための国際標準です。これにより、標準化された形式で任意の言語のほぼすべての文字を表現し、テキストファイルやWebページなどの外部ソースとの間でそれらの文字を読み書きできます。このセクションで説明するように、Swiftの文字列と文字の型は完全にUnicodeに準拠しています。
3.11.1. Unicodeスカラー値
舞台裏では、Swiftのネイティブ文字列型はUnicodeスカラー値から構築されています。 Unicodeスカラー値は、文字または修飾子の一意の21ビット数です。たとえば、LATIN SMALL LETTER A( “a”)の場合はU+0061、FRONT-FACING BABY CHICK( “🐥”)の場合はU+1F425です。
すべての21ビットUnicodeスカラー値が文字に割り当てられるわけではないことに注意してください。一部のスカラーは、将来の割り当てまたはUTF-16エンコーディングでの使用のために予約されています。文字に割り当てられたスカラー値には、通常、上記の例のLATIN SMALL LETTERAやFRONT-FACINGBABYCHICKなどの名前も付いています。
3.11.2. 拡張書記素クラスター
Swiftの文字型のすべてのインスタンスは、単一の拡張書記素クラスターを表します。拡張書記素クラスターは、1つ以上のUnicodeスカラーのシーケンスであり、(組み合わせると)1つの人間が読める文字を生成します。
これが例です。文字éは、単一のUnicodeスカラーé(LATIN SMALL LETTER E WITH ACUTE、またはU+00E9)として表すことができます。 ただし、同じ文字をスカラーのペアとして表すこともできます。標準の文字e(LATIN SMALL LETTER E、またはU+0065)の後に、COMBINING ACUTE ACCENTスカラー(U+0301)が続きます。COMBINING ACUTE ACCENTスカラーは、その前のスカラーにグラフィカルに適用され、Unicode対応のテキストレンダリングシステムによってレンダリングされるときにeをéに変換します。
どちらの場合も、文字éは、拡張された書記素クラスターを表す単一のSwift文字値として表されます。最初のケースでは、クラスターに単一のスカラーが含まれています。2番目のケースでは、2つのスカラーのクラスターです。
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
// eAcuteは é, combinedEAcuteはé拡張書記素クラスターは、多くの複雑なスクリプト文字を単一の文字値として表す柔軟な方法です。たとえば、韓国語のアルファベットのハングル音節は、合成済みまたは分解済みのシーケンスとして表すことができます。これらの表現は両方とも、Swiftでは単一の文字値として適格です。
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposedは한, decomposedは한拡張書記素クラスターを使用すると、マークを囲むためのスカラー(COMBINING ENCLOSING CIRCLE、U+20DDなど)を使用して、他のUnicodeスカラーを単一の文字値の一部として囲むことができます。
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcuteはé⃝地域インジケータシンボルのUnicodeスカラーをペアで組み合わせて、単一の文字値を作成できます。たとえば、この地域インジケータシンボル文字U(U+1F1FA)と地域インジケータ記号文字S(U+1F1F8)の組み合わせは次のとおりです。
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUSは🇺🇸3.12. 文字のカウンティング
文字列内の文字値のカウントを取得するには、文字列のcountプロパティを使用します。
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// "unusualMenagerie has 40 characters"を出力するSwiftが文字値に拡張書記素クラスターを使用しているということは、文字列の連結と変更が文字列の文字数に常に影響するとは限らないことに注意してください。
たとえば、新しい文字列を4文字の単語cafeで初期化し、その文字列の最後にCOMBINING ACUTE ACCENT(U+0301)を追加すると、結果の文字列の文字数は4のままになり、 4番目の文字はeではなくé:
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// "the number of characters in cafe is 4"を出力する
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// "the number of characters in café is 4"を出力する注意
拡張書記素クラスターは、複数のUnicodeスカラーで構成できます。これは、異なる文字(および同じ文字の異なる表現)が格納するために異なる量のメモリを必要とする可能性があることを意味します。このため、Swiftの文字は、文字列の表現内でそれぞれ同じ量のメモリを使用するわけではありません。その結果、文字列内の文字数は、拡張された書記素クラスターの境界を決定するために文字列を反復処理せずに計算することはできません。特に長い文字列値を使用している場合は、その文字列の文字を決定するために、countプロパティが文字列全体のUnicodeスカラーを反復処理する必要があることに注意してください。
countプロパティによって返される文字の数は、同じ文字を含むNSStringのlengthプロパティと常に同じであるとは限りません。NSStringの長さは、文字列内のUnicode拡張書記素クラスターの数ではなく、文字列のUTF-16表現内の16ビットコードユニットの数に基づいています。
3.13. 文字列へのアクセスと変更
文字列にアクセスして変更するには、そのメソッドとプロパティを使用するか、添え字構文を使用します。
3.13.1. 文字列インデックス
各文字列値には、文字列内の各文字の位置に対応するインデックス型String.Indexが関連付けられています。
上記のように、文字が異なれば保存に必要なメモリ量も異なる可能性があるため、特定の位置にある文字を判別するには、その文字列の最初または最後から各Unicodeスカラーを反復処理する必要があります。このため、Swift文字列に整数値でインデックスを付けることはできません。
startIndexプロパティを使用して、文字列の最初の文字の位置にアクセスします。endIndexプロパティは、文字列の最後の文字の後の位置です。その結果、endIndexプロパティは文字列の添え字に対する有効な引数ではありません。文字列が空の場合、startIndexとendIndexは等しくなります。
Stringのindex(before:)メソッドとindex(after:)メソッドを使用して、特定のインデックスの前後のインデックスにアクセスします。指定されたインデックスからさらに離れたインデックスにアクセスするには、これらのメソッドの1つを複数回呼び出す代わりに、index(_:offsetBy:)メソッドを使用できます。
添え字構文を使用して、特定の文字列インデックスの文字にアクセスできます。
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a文字列の範囲外のインデックスまたは文字列の範囲外のインデックスの文字にアクセスしようとすると、ランタイムエラーがトリガーされます。
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Errorインデックスプロパティを使用して、文字列内の個々の文字のすべてのインデックスにアクセスします。
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// "G u t e n T a g ! "を出力する注意
コレクションプロトコルに準拠する任意の型で、startIndexプロパティとendIndexプロパティ、およびindex(before:)、index(after:)、およびindex(_:offsetBy:)メソッドを使用できます。これには、ここに示すようにStringと、Array、Dictionary、Setなどのコレクション型が含まれます。
3.13.2. 挿入と削除
指定されたインデックスの文字列に単一の文字を挿入するには、insert(_:at:)メソッドを使用し、指定されたインデックスの別の文字列の内容を挿入するには、insert(contentsOf:at:)メソッドを使用します。
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcomeは"hello!"に等しくなります
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcomeは"hello there!"に等しくなります指定されたインデックスの文字列から1文字を削除するには、remove(at:)メソッドを使用し、指定された範囲の部分文字列を削除するには、removeSubrange(_:)メソッドを使用します。
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcomeは"hello there"に等しくなります
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcomeは"hello"に等しくなります注意
RangeReplaceableCollectionプロトコルに準拠する任意のタイプで、insert(:at:)、insert(contentsOf:at:)、remove(at:)、およびremoveSubrange( :)メソッドを使用できます。これには、ここに示すようにStringと、Array、Dictionary、Setなどのコレクション型が含まれます。
3.13.3. 部分文字列
文字列から部分文字列を取得すると(たとえば、添え字またはprefix(_:)などのメソッドを使用して)、結果は別の文字列ではなく、部分文字列のインスタンスになります。Swiftの部分文字列には、文字列とほとんど同じメソッドがあります。つまり、文字列を操作するのと同じ方法で部分文字列を操作できます。ただし、文字列とは異なり、文字列に対してアクションを実行している間は、短時間だけ部分文字列を使用します。結果を長期間保存する準備ができたら、部分文字列を文字列のインスタンスに変換します。 例えば:
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// 始まりは「こんにちは」
// 結果を文字列に変換して長期保存します。
let newString = String(beginning)文字列と同様に、各部分文字列には、部分文字列を構成する文字が格納されるメモリ領域があります。文字列と部分文字列の違いは、パフォーマンスの最適化として、部分文字列は元の文字列を格納するために使用されるメモリの一部、または別の部分文字列を格納するために使用されるメモリの一部を再利用できることです。(文字列の最適化は似ていますが、2つの文字列がメモリを共有している場合、それらは等しくなります。)このパフォーマンスの最適化は、文字列または部分文字列のいずれかを変更するまで、メモリをコピーするパフォーマンスコストを支払う必要がないことを意味します。上記のように、部分文字列は長期保存には適していません。元の文字列の保存を再利用するため、部分文字列のいずれかが使用されている限り、元の文字列全体をメモリに保持する必要があります。
上記の例では、greetingは文字列です。つまり、文字列を構成する文字が格納されるメモリ領域があります。beginはgreetingの部分文字列であるため、greetingが使用するメモリを再利用します。対照的に、newStringは文字列です。部分文字列から作成される場合、独自のストレージがあります。次の図は、これらの関係を示しています。
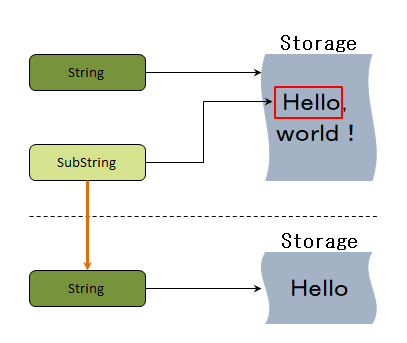
注意
StringとSubstringはどちらもStringProtocolプロトコルに準拠しています。つまり、文字列操作関数がStringProtocol値を受け入れると便利なことがよくあります。このような関数は、String値またはSubstring値のいずれかを使用して呼び出すことができます。
3.13.4. 文字列の比較
Swiftは、テキスト値を比較する3つの方法を提供します。文字列と文字の同等性、プレフィックスの同等性、およびサフィックスの同等性です。
3.13.4.1. 文字列と文字の同等性
文字列と文字の同等性は、比較演算子で説明されているように、「等しい」演算子(==)と「等しくない」演算子(!=)でチェックされます。
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// 「これらの2つの文字列は等しいと見なされます」と出力します2つの文字列値(または2つの文字値)は、それらの拡張書記素クラスターが正規に同等である場合、等しいと見なされます。 拡張書記素クラスターは、舞台裏で異なるUnicodeスカラーから構成されている場合でも、同じ言語的意味と外観を持っていれば、標準的に同等です。
たとえば、ラテン文字Eとアキュートアクセント(U+00E9)は、ラテン文字E(U+0065)の後にアキュートアクセント(U+0301)を組み合わせたものと正規に同等です。これらの拡張書記素クラスターは両方とも、文字éを表す有効な方法であるため、正規に同等であると見なされます。
// LATIN SMALL LETTER E WITH ACUTEを使用する"Voulez-vous un café?"
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// LATIN SMALL LETTER EとCOMBINING ACUTE ACCENTを使用する"Voulez-vous un café?"
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// "These two strings are considered equal"と出力します。逆に、英語で使用されるラテン大文字A(U+0041、または「A」)は、ロシア語で使用されるキリル大文字A(U+0410、または「А」)と同等ではありません。 文字は視覚的に似ていますが、同じ言語的意味はありません。
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent.")
}
// "These two characters are not equivalent."を出力します。注意
Swiftでの文字列と文字の比較は、ロケールに依存しません。
3.13.4.2. プレフィックスとサフィックスの同等性
文字列に特定の文字列プレフィックスまたはサフィックスがあるかどうかを確認するには、文字列のhasPrefix(:)メソッドとhasSuffix(:)メソッドを呼び出します。どちらも、String型の単一の引数を取り、ブール値を返します。
以下の例では、シェイクスピアのロミオとジュリエットの最初の2つの行為のシーンの場所を表す文字列の配列を検討しています。
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]hasPrefix(_:)メソッドをromeoAndJuliet配列とともに使用して、劇の第1幕のシーンの数を数えることができます。
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// "There are 5 scenes in Act 1"を出力します。同様に、hasSuffix(_:)メソッドを使用して、Capuletの邸宅とFriarLawrenceのセル内の周辺で発生するシーンの数をカウントします。
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// "6 mansion scenes; 2 cell scenes"を出力します。注意
hasPrefix(:)メソッドとhasSuffix(:)メソッドは、文字列と文字の同等性で説明されているように、各文字列の拡張書記素クラスター間で文字ごとの正規等価比較を実行します。
3.14. 文字列のUnicode表現
Unicode文字列がテキストファイルまたはその他のストレージに書き込まれると、その文字列内のUnicodeスカラーは、Unicodeで定義されたいくつかのエンコード形式のいずれかでエンコードされます。各フォームは、コードユニットと呼ばれる小さなチャンクで文字列をエンコードします。これらには、UTF-8エンコード形式(文字列を8ビットコード単位としてエンコードする)、UTF-16エンコード形式(文字列を16ビットコード単位としてエンコードする)、およびUTF-32エンコード形式(文字列を32ビットコード単位としてエンコードする)。
Swiftは、文字列のUnicode表現にアクセスするためのいくつかの異なる方法を提供します。for-inステートメントを使用して文字列を反復処理し、Unicode拡張書記素クラスターとして個々の文字値にアクセスできます。このプロセスについては、「文字の操作」で説明しています。
または、他の3つのUnicode準拠表現のいずれかで文字列値にアクセスします。
- UTF-8コードユニットのコレクション(文字列のutf8プロパティでアクセス)
- UTF-16コードユニットのコレクション(文字列のutf16プロパティでアクセス)
- 文字列のUTF-32エンコーディング形式(文字列のunicodeScalarsプロパティでアクセス)に相当する21ビットのUnicodeスカラー値のコレクション
以下の各例は、文字D、o、g、!(DOUBLE EXCLAMATION MARK、またはUnicodeスカラーU+203C)と🐶文字(DOG FACE、またはUnicodeスカラーU + 1F436)で構成される次の文字列の異なる表現を示しています。:
let dogString = "Dog‼🐶"3.14.1. UTF-8表現
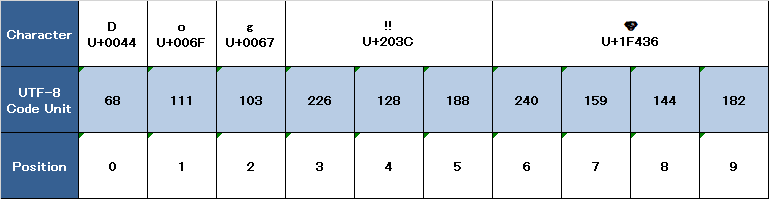
utf8プロパティを反復処理することにより、文字列のUTF-8表現にアクセスできます。このプロパティのタイプはString.UTF8Viewです。これは、文字列のUTF-8表現の各バイトに1つずつ、符号なし8ビット(UInt8)値のコレクションです。
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// "68 111 103 226 128 188 240 159 144 182 "を出力します。上記の例では、最初の3つの10進codeUnit値(68、111、103)は、文字D、o、およびgを表し、そのUTF-8表現はASCII表現と同じです。次の3つの10進codeUnit値(226、128、188)は、DOUBLE EXCLAMATIONMARK文字の3バイトUTF-8表現です。最後の4つのcodeUnit値(240、159、144、182)は、DOGFACE文字の4バイトのUTF-8表現です。
3.14.2. UTF-16表現
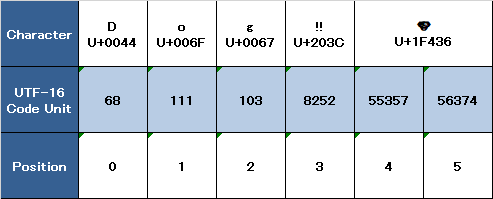
utf16プロパティを反復処理することにより、文字列のUTF-16表現にアクセスできます。このプロパティのタイプはString.UTF16Viewです。これは、文字列のUTF-16表現の16ビットコードユニットごとに1つずつ、符号なし16ビット(UInt16)値のコレクションです。
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// "68 111 103 8252 55357 56374 "を出力します。この場合も、最初の3つのcodeUnit値(68、111、103)は文字D、o、およびgを表し、そのUTF-16コード単位は文字列のUTF-8表現と同じ値を持ちます(これらのUnicodeスカラーはASCII文字を表すため) )。
4番目のcodeUnit値(8252)は、16進値203Cに相当する10進数であり、DOUBLE EXCLAMATIONMARK文字のUnicodeスカラーU+203Cを表します。 この文字は、UTF-16では単一のコード単位として表すことができます。
5番目と6番目のcodeUnit値(55357と56374)は、DOGFACE文字のUTF-16サロゲートペア表現です。これらの値は、U+D83Dのハイサロゲート値(10進値55357)とU+DC36のローサロゲート値(10進値56374)です。
この場合も、最初の3つのcodeUnit値(68、111、103)は文字D、o、およびgを表し、そのUTF-16コード単位は文字列のUTF-8表現と同じ値を持ちます(これらのUnicodeスカラーはASCII文字を表すため)。
4番目のcodeUnit値(8252)は、16進値203Cに相当する10進数であり、DOUBLE EXCLAMATIONMARK文字のUnicodeスカラーU+203Cを表します。 この文字は、UTF-16では単一のコード単位として表すことができます。
5番目と6番目のcodeUnit値(55357と56374)は、DOGFACE文字のUTF-16サロゲートペア表現です。これらの値は、U+D83Dのハイサロゲート値(10進値55357)とU+DC36のローサロゲート値(10進値56374)です。
3.14.3. Unicodeスカラー表現
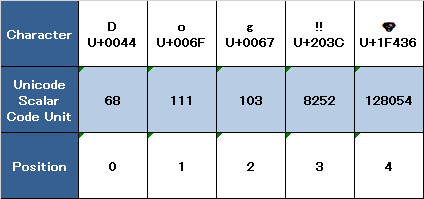
unicodeScalarsプロパティを反復処理することにより、文字列値のUnicodeスカラー表現にアクセスできます。このプロパティはUnicodeScalarView型であり、UnicodeScalar型の値のコレクションです。
各UnicodeScalarには、UInt32値内で表されるスカラーの21ビット値を返すvalueプロパティがあります。
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// "68 111 103 8252 128054 "を出力します。最初の3つのUnicodeScalar値(68、111、103)の値プロパティは、再び文字D、o、およびgを表します。
4番目のcodeUnit値(8252)も、16進値203Cと10進数で同等です。これは、DOUBLE EXCLAMATIONMARK文字のUnicodeスカラーU+203Cを表します。
5番目で最後のUnicodeScalarのvalueプロパティ128054は、DOGFACE文字のUnicodeスカラーU+1F436を表す16進値1F436と10進数で同等です。
値のプロパティをクエリする代わりに、各UnicodeScalar値を使用して、文字列補間などで新しい文字列値を作成することもできます。
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶
